😒 Почти 80% программистов несчастны на работе
|
Хотя программисты хорошо зарабатывают и часто могут работать удаленно, многие все равно недовольны. Недавний опрос айтишников на Stack Overflow (65,4 тысяч разработчиков из 185 стран) выявил несколько шокирующих фактов: |
- 32,1% профессиональных программистов ненавидят свою работу.
- 47,7% разработчиков признались, что утратили мотивацию, выгорели и не испытывают никакого энтузиазма.
- Лишь 20,2% утверждают, что вполне довольны своей нынешней работой.
|
Согласно опросу, основные причины раздражения разработчиков – технический долг и сложность технологического стека, с которым они должны работать. Добавьте к этому постоянную необходимость выполнения задач в нереалистичные сроки, бесконечные совещания с боссами и массовые увольнения по всей отрасли... Пожалуй, 80% звучит вполне логично, если не сказать – занижено. |
🏔️ Python укрепляет позиции в индексе TIOBE
|
Популярность Python выросла с 16,12% в июле до 18,04% в августе – очень значительный скачок за такой короткий период, – и теперь «Питон» опережает второй язык в списке, C++, на рекордные 8%. «Вероятно, Python станет самым популярным языком программирования в истории», – написал генеральный директор TIOBE Software Пол Янсен в ежемесячном выпуске индекса. |
Янсен отметил, что лидерство Python неоспоримо, и добавил, что его единственными возможными конкурентами в будущем могут стать только Rust и Kotlin. Они стремительно приближаются к топ-10, и все же на достижение сопоставимых с «Питоном» позиций у них уйдет несколько лет. Rust сейчас занимает 14-е место, а Kotlin – 18-е. Популярность Kotlin значительно выросла за год – в августе 2023 года он был на скромном 27-м месте. |
💾 7 техник масштабирования и повышения производительности баз данных
|
Масштабирование улучшает производительность и повышает надежность систем хранения данных путем оптимизации использования ресурсов и распределения нагрузки. Применение подходящей техники помогает: |
- Ускорить обработку запросов и увеличить пропускную способность базы данных, что критически важно для высоконагруженных приложений.
- Улучшить отказоустойчивость и производительность за счет распределения нагрузки между несколькими узлами (горизонтальное масштабирование).
- Повысить производительность за счет увеличения мощности обработки данных на одном узле (вертикальное масштабирование).
- Уменьшить время отклика за счет сокращения количества обращений к диску за данными (кэширование).
- Оптимизировать использование ресурсов базы данных за счет улучшения эффективности запросов и снижения необходимости в сложных операциях соединения таблиц (индексация и денормализация).
|
Рассмотрим самые популярные техники масштабирования подробнее. |
Индексация в базах данных действует по аналогии с разделом «содержание» в книге – позволяет быстро находить и извлекать конкретную информацию без сканирования всей базы в поисках каждой отдельной записи. |
Материализованные представления
|
Материализованное представление — снимок результата запроса, хранящийся отдельно от исходных данных и поддерживаемый независимо. Это своего рода саммари, краткое содержание. |
Материализованное представление |
Денормализация заключается в дублировании данных по нескольким таблицам для оптимизации производительности запросов. Предположим, у нас есть две таблицы: одна для клиентов (Customers) и другая для заказов (Orders). В обычной ситуации, когда мы следуем правилам нормализации данных (то есть стараемся избежать дублирования информации), в таблице Orders будет только ссылка на соответствующего клиента из таблицы Customers. Это значит, что для получения информации о заказе вместе с деталями клиента нам придется «соединить» эти две таблицы с помощью специального SQL-запроса (join).
Однако по мере роста количества заказов операция соединения может стать «узким местом» в производительности, потому что она требует дополнительных вычислений и времени на обработку. Здесь на помощь приходит денормализация: мы умышленно дублируем данные в разных таблицах для улучшения производительности запросов.
В нашем примере можно добавить поле CustomerName непосредственно в таблицу Orders. Таким образом, когда нам нужны детали заказа вместе с именем клиента, можно получить всю интересующую нас информацию из одной таблицы без необходимости выполнять операцию соединения. Это значительно ускоряет выполнение запросов. |
Вертикальное масштабирование
|
Вертикальное масштабирование заключается в увеличении аппаратных ресурсов сервера. Это установка более мощных CPU и большего объема ОЗУ, замена устаревших HDD на SSD. |
Вертикальное масштабирование |
Есть пределы вертикального масштабирования сервера до достижения некоторых ограничений, в том числе по стоимости. Сбой сервера может привести к отказу в работе базы данных.
|
Кэширование состоит в хранении часто запрашиваемых данных в высокоскоростном слое хранения, отдельно от основной базы данных. |
Когда приложение получает запрос на данные, оно сначала проверяет кэш. Если данные находятся в кэше, они быстро извлекаются без обращения к базе данных. Если данные отсутствуют в кэше, приложение извлекает их из базы данных и сохраняет копию в кэше для будущих запросов.
|
Кэширование особенно полезно для данных, которые редко изменяются, но часто запрашиваются, поскольку позволяет избежать частых и ресурсоемких обращений к базе данных. |
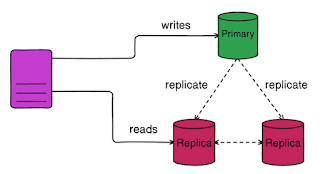
Репликация заключается в создании и поддержании нескольких копий данных на разных серверах или узлах. Эта техника обеспечивает высокую доступность и отказоустойчивость базы данных. В типичной модели репликации «лидер-последователь» один узел назначается лидером, а остальные становятся последователями. |
Лидер обрабатывает все операции записи, обеспечивая их согласованность и целостность. Когда данные изменяются или добавляются в базу данных лидера, эти изменения автоматически распространяются на узлы-последователи. Лидер также может обрабатывать критические операции чтения, где требуется высокая степень согласованности. Последователи обычно используются для обработки запросов на чтение, чтобы распределить нагрузку и улучшить производительность системы.
|
Улучшенная производительность чтения. Высокая доступность даже в случае сбоя нескольких узлов-последователей. Горизонтальное распределение нагрузки.
|
Шардинг – это техника, которая разделяет одну большую базу данных на меньшие, более управляемые единицы, называемые шардами. Основные стратегии разделения базы: |
Шардинг на основе диапазона значений ключа шардинга. Хеш-шардинг: для определения целевого шарда к ключу шардинга применяется хеш-функция. Директорный шардинг: для сопоставления соответствия ключа шардинга с соответствующим шардом поддерживается отдельная таблица.
|
Позволяет горизонтально масштабировать базу данных. Запросы и операции записи обрабатываются параллельно. Снижение затрат на оборудование по сравнению с вертикальным масштабированием.
|
Вносит дополнительную сложность. Перебалансировка данных между шардами может быть сложной и времязатратной процедурой. Объединение данных между шардами может стать нетривиальной задачей.
| sqlite-vec – небольшое расширение для базы данных SQLite. Оно позволяет быстро искать векторы, состоящие из чисел с плавающей запятой (float), целых чисел (int8) и бинарных данных. Это расширение написано на чистом языке C, не требует дополнительных зависимостей и может работать на любой платформе, где поддерживается SQLite, включая Linux, MacOS, Windows, браузеры с поддержкой WASM (WebAssembly) и даже Raspberry Pi.
git-authorship позволяет определить, кто написал конкретные строки кода в вашем репозитории Git. Он не занимается управлением авторскими правами и соглашениями с контрибьюторами, но помогает четко идентифицировать разработчиков и их вклад в проект.
Greenmask предлагает широкий спектр функций для резервного копирования, анонимизации и маскировки данных. Greenmask написан полностью на Go и включает портированные библиотеки PostgreSQL, что делает его независимым от платформы. Не требует изменений в схеме базы данных и совместим со всеми стандартными утилитами PostgreSQL.
|
SQLpage позволяет создавать веб-страницы исключительно на основе SQL-запросов. Этот инструмент помогает дата-сайентистам и аналитикам быстро создавать мощные приложения. С помощью SQLpage вы пишете простые файлы .sql, содержащие запросы к базе данных для выбора, группировки, обновления, вставки и удаления данных, и получаете хорошо оформленные веб-страницы, отображающие данные в виде текста, списков, таблиц, графиков и форм. |
SQLpage превращает запросы в веб-страницу |
ngtop помогает быстро и эффективно собирать и анализировать данные о запросах к веб-сайту, используя лог-файлы Nginx. Позволяет задавать разные критерии фильтрации для запросов, такие как URL, пользовательский агент, IP-адрес, реферер и статус ответа.
dir-assistant позволяет общаться с файлами в текущей директории, используя локальную LLM или API любого ИИ-провайдера. Поддерживает разные платформы, в том числе CPU (OpenBLAS), Cuda, ROCm, Metal, Vulkan и SYCL.
|
|
|
Понравилась ли вам эта рассылка? |
|
|
Вы получили это письмо, потому что подписались на нашу рассылку. Если вы больше не хотите получать наши письма, нажмите здесь.
|
|
|
|