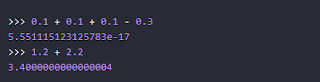🗣️ Самые популярные языки 2024 года по версии IEEE Spectrum
|
IEEE Spectrum опубликовал ежегодный рейтинг языков программирования. Этот рейтинг учитывает 3 основных аспекта популярности ЯП: - Уровень фактического использования профессиональными разработчиками.
- Общие тренды (поисковые запросы, обсуждения на Stack Overflow, Discord и т. п.).
- Упоминания языка в открытых вакансиях.
С учетом всех этих нюансов тройной рейтинг выглядит так: |
Основные выводы составителей рейтинга: - Python продолжает укреплять свою доминирующую позицию. Его популярность объясняется двумя важными факторами – огромным спросом в ИИ-разработке и широчайшим использованием в учебных целях. Лишь в рейтинге работодателей Python немного уступает другому языку – SQL, спрос на который отражает глобальную тенденцию к использованию облачных технологий и распределенных систем, где эффективное управление данными и их обработка – это ключевые аспекты разработки.
- Java, JavaScript и C++ продолжают удерживать высокие позиции, но особенно интересно то, что происходит немного ниже: TypeScript, который является надмножеством JavaScript, значительно поднялся во всех рейтингах, особенно в категории «Вакансии», где он занимает 4-е место против 11-го год назад – статическая типизация переменных оказалась очень важным преимуществом для разработчиков и работодателей.
- Rust тоже заметно вырос в популярности. Подобно C и C++, Rust используется для разработки системного ПО, но, в отличие от этих языков, Rust обеспечивает безопасность памяти – это преимущество стало особенно важным на фоне неуклонного роста кибератак: отчет специалистов по кибербезопасности Белого дома (.pdf) призывает к использованию безопасных языков вместо C и C++. Стоит отметить, что популярность С явно идет на спад – в рейтинге разработчиков язык переместился с 4-го места на 9-е, а в рейтинге работодателей – с 7-го на 13-е.
- Apex и Solidity впервые появились в рейтинге. Apex создан для разработки бизнес-приложений, которые используют Salesforce-сервер в качестве бэкенда, а Solidity предназначен для создания смарт-контрактов в блокчейне Ethereum.
- Fortran и Cobol остаются в рейтинге, несмотря на свой почтенный возраст (каждому около 65 лет). Разработчики на Fortran, судя по требованиям в вакансиях, должны принадлежать к избранной касте людей, которые, помимо программирования, хорошо разбираются в субъядерной физике и имеют соответствующие допуски. Вакансий по Cobol больше – многие финансовые и правительственные учреждения все еще используют инфраструктуру, устаревшую несколько десятилетий назад.
|
🐍 7 малоизвестных возможностей стандартной библиотеки Python
|
Продвинутые структуры данных – collections
|
Словари и списки Python отлично подходят для большинства простых приложений и скриптов, но могут быть недостаточно эффективными для более сложной организации данных (и для решения соревновательных задач). Более мощные контейнеры для хранения данных в памяти предоставляет один из стандартных модулей Python – collections: - Deque – двусвязная очередь; похожа на список, но обеспечивает более эффективное добавление и удаление элементов с любой стороны.
- Counter – подкласс словаря для подсчета элементов.
- ChainMap – метасловарь, предоставляющий единообразное сопоставление ключей и значений из нескольких словарей без копирования данных.
- OrderedDict – словарь, который сохраняет порядок пар ключ-значение, поддерживает операторы | и |= , отлично подходит для реализации любого варианта кэша.
- namedtuple – функция-фабрика, создающая подкласс кортежа с именованными полями. Лучше подходит для ООП и решения многих типов олимпиадных задач, чем обычный словарь.
- defaultdict – словарь с предварительно заполненными значениями (всеми или некоторыми). Полезен, когда нужно, например, в процессе скрапинга предоставить значения для полей, которые могут отсутствовать на страницах.
- UserDict, UserList и UserString – обертки dict, list и str для дальнейшей подклассификации.
|
Модуль contextlib предоставляет функции-хэлперы для работы с менеджерами контекста в вашем коде. Например, можно использовать аннотацию @contextmanager для превращения своей собственной функции в такую, которая может быть использована с помощью синтаксиса with. |
Абстрактный пример использования @contextmanager |
Точные вычисления с дробями и числами с плавающей запятой
|
Из-за технических особенностей представления чисел с плавающей запятой обычные вычисления с ними могут давать неожиданные результаты: |
Это математически некорректно и, более того, может стать серьезной проблемой для приложения, выполняющего точные (особенно финансовые, научные или инженерные) расчеты. Проблему решает модуль decimal, который корректирует вычисления таким образом, чтобы мы получали правильный результат (в пределах конфигурируемого уровня точности): |
Для корректной работы с дробными значениями используется модуль fraction: |
Дизассемблирование байт-кода
|
Интерпретатор Python реализован как стековая машина – он использует стек для хранения и манипулирования данными во время выполнения кода. Когда вы запускаете код на Python, он сначала компилируется в специфический для Python байт-код. Этот байт-код – не машинный код, а скорее промежуточный формат, который выполняется виртуальной машиной Python. Для целей отладки или оптимизации производительности бывает полезно преобразовать байт-код в некое подобие псевдо-ассемблера. Стандартная установка Python поставляется с модулем dis, который позволяет выполнить это дизассемблирование – dis принимает единицы кода Python (например, функцию) и преобразует их в читаемый формат, показывающий каждую инструкцию байт-кода: |
Статистические вычисления
|
Модуль statistics в Python предоставляет набор инструментов для простых статистических вычислений – они пригодятся в случаях, когда возможности мощных библиотек типа pandas или NumPy избыточны: |
Открытие URL или локального HTML-файла
|
С помощью webbrowser из Python-кода можно вызвать браузер для просмотра URL: |
import webbrowser # Открывает страницу в новой вкладке браузера webbrowser.open_new_tab('https://proglib.io') |
Или локальной веб-страницы: |
import os import webbrowser file_url = 'file://' + os.path.realpath('index.html') # Открывает локальный файл в браузере webbrowser.open(file_url) |
Упаковка Python-программ в один файл
|
Распространение программ и скриптов на Python связано с многочисленными проблемами: - Пользователи, не знакомые с программированием, могут случайно повредить код или не разобраться, как его запустить.
- Даже если у пользователей установлен Python, у них могут отсутствовать необходимые зависимости, не будет настроено виртуальное окружение и так далее.
- Может возникнуть конфликт версий.
Чтобы избежать этих проблем, Python предоставляет модуль zipapp, который позволяет упаковать код в единственный файл. Этот файл (с расширением .pyz) не будет исполняемым (zipapp работает как архиватор), и запустить его можно только при условии наличия Python в системе, зато все остальные проблемы он решает. Эта команда упакует содержимое директории myappdir в файл myapp.pyz и добавит шебанг для указания интерпретатора Python: |
$ python -m zipapp myappdir -p "/usr/bin/env python3" -o myapp.pyz |
import zipapp zipapp.create_archive( source="myappdir", target="myapp.pyz", interpreter="/usr/bin/env python3" ) |
🛜 5 стратегий оптимизации производительности API
|
Разработка API кажется делом простым и понятным, но эксплуатация – совсем другое дело: рано или поздно нагрузка вырастет настолько, что пользователи будут недовольны – и это понятно, никому не хочется использовать медленный API. Решить эту проблему можно только с помощью оптимизации, а выполнить ее можно одним из перечисленных ниже способов. |
В теории суть кэширования проста: - Нужно хранить часто запрашиваемые данные в кэше (высокоскоростном буферном хранилище), чтобы предоставлять быстрый доступ к ним, когда это необходимо.
- Если какого-то запроса в кэше нет, данные загружаются из базы данных.
- Если какие-то данные в кэше больше не пользуются спросом или утратили актуальность, нужно их удалить.
Практическая реализация кэширования сложнее – нужно решить две главные проблемы: - Выбрать оптимальную стратегию кэширования (неправильный выбор может привести к снижению производительности или к использованию устаревших данных). Чаще всего используется кэширование на стороне, кэширование со сквозным чтением или сквозной записью и кэш с отложенной записью.
- Найти эффективный подход к инвалидации кэша — процессу удаления устаревших данных, который обеспечивает актуальность информации.
|
Основные стратегии кэширования |
Готовое решение можно подсмотреть у высоконагруженных платформ – например, разработчики LinkedIn рассказали, как им удалось обеспечить больше 4,8 млн запросов в секунду с помощью кэша Couchbase, а программисты Facebook* поделились секретами масштабирования Memcache. |
Масштабирование с помощью балансировки нагрузки
|
Этот метод позволяет распределить нагрузку между несколькими серверами, чтобы улучшить производительность и надежность приложения. Главная проблема здесь – найти оптимальный способ распределения входящих запросов. Решением этой задачи занимается балансировщик нагрузки: он равномерно распределяет запросы между серверами, предотвращая перегрузку любого из них. Балансировщик нагрузки не только улучшает производительность, но и делает приложение более надежным, поскольку если один сервер выйдет из строя, другие могут продолжать обрабатывать запросы. | Балансировщик нагрузки лучше всего подходит для приложений без сохранения состояния, которые легко масштабируются горизонтально |
Иногда невозможно решить несколько сложных задач одновременно. В таких случаях лучший подход – отложить их на потом. С помощью асинхронной обработки можно сообщить клиентам, что их запросы зарегистрированы и находятся в процессе выполнения. Затем сервер обрабатывает запросы по одному и сообщает результаты клиентам в порядке очереди. Этот метод позволяет вашему серверу приложений не выйти из строя и обеспечить максимальную производительность. Однако, конечно же, асинхронная обработка подходит не для каждого приложения. |
Если ваш API возвращает большое количество записей, нужно рассмотреть пагинацию – это процесс разбиения данных на отдельные страницы или пакеты. С помощью пагинации можно ограничить количество записей в каждом запросе, тем самым уменьшая объем передаваемых данных по сети. Это улучшает время ответа API с точки зрения клиента. Например, вместо того чтобы загружать 1000 записей сразу, можно загружать их по 20–50 за раз. Клиенту будет предложено получить первую страницу из списка записей. Когда клиент захочет увидеть больше записей, он может запросить следующую страницу и так далее. |
Эта техника улучшает производительность приложений, которым необходимо часто подключаться к базам данных, особенно в системах с высокой степенью конкурентности. Вместо создания нового соединения с базой данных для каждого запроса, что может существенно замедлить работу из-за времени, необходимого на установку соединения, пул соединений позволяет заранее создать набор активных соединений, которые могут быть повторно использованы разными запросами. |
* Facebook принадлежит компании Meta, деятельность которой признана экстремистской и запрещена на территории РФ. |
|
|
Понравилась ли вам эта рассылка? |
|
|
Вы получили это письмо, потому что подписались на нашу рассылку. Если вы больше не хотите получать наши письма, нажмите здесь.
|
|
|
|